
MultiStream 一种优化 SSD GC 性能的技术
NVME
传统的存储接口协议例如 SCSI,SATA,SAS都是为HDD设计的,SSD的性能受制于这些协议,后来SSD从SATA转向了带宽大延迟小的协议PCIe。这些host-to-device物理层协议都需要 host-to-controller 接口来实现驱动。比如SATA的控制器接口(软件)就是AHCI。为了让PCIe发挥出应有实力,NVME出现了。
单一PCIe通道支持1GB/s的传输。典型的是x4PCIe支持4GB/s,现代的X86支持到x16的PCIe。存储接口的限制取决于PCIe的通道。
硬件通路上NVME也快很多,因为PCIe root port直接和系统连接,所以数据的延迟小很多。
传统的SATA i/o 路径中,达到块设备层的请求被插入到请求队列,Elevator将重新排序以将多个请求组合成顺序的。虽然HDD因其随机访问慢这样做有情可原,但是SSD完全多余。SSD仅仅FIFO即可。
NVME标准绕过了传统的块设备层请求队列,相反用一对 submission 和 completion 队列机制,NVME支持达64K个 I/O 队列和每个队列多达 64K 个命令。这些队列一般存在host memory中,由NVME驱动和NVME控制器协作管理。当完成SQ队列中的命令,去通知CQ的门铃来告诉主机,这样异步的执行方法减少了CPU的占用。
LevelDB
简而言之,LevelDb是能够处理十亿级别规模Key-Value型数据持久性存储的C++ 程序库。如果了解Bigtable的话,有两个核心的部分:Master Server和Tablet Server。其中Master Server做一些管理数据的存储以及分布式调度工作,实际的分布式数据存储以及读写操作是由Tablet Server完成的,而LevelDb则可以理解为一个简化版的Tablet Server。(负责单机存储) 写入时使用WAL策略,先写入log,写入成功一次操作后,把操作插入Memtable。Log文件在系统中的作用主要是用于系统崩溃恢复而不丢失数据。当Memtable插入的数据占用内存到了一个界限后,内存的记录导出到外存文件中,LevelDb后台调度会将Immutable Memtable的数据导出到磁盘,形成一个新的SSTable文件。
SST文件不可修改,慢慢地,失效地数据越来越多,所以搜索一个 data record 有可能查询很多地文件,这叫 “读放大”。为了避免,要进行压缩处理。
SSTable就是由内存中的数据不断导出并进行Compaction操作后形成的,而且SSTable的所有文件是一种层级结构。level越低的生命期越短,压缩越快,Level越高的生命期越长,压缩更慢。
MultiStream (RocksDB)
GC已经是SSD性能下降的关键原因。为了降低GC。之前已经用了很多方法,比如1.用时间戳区分冷热数据(需要额外的内存记录数据的历史访问信息,冷热的区分很难做到,无法预测未来的访问)2.在SSD中增加一个区域用于增加GC效率(流行做法) 3.主机用TRIM指令告诉设备那些LBA已经失效,这样GC就可以得到更多信息以判断哪些不需要copy(听起来不错)。
虽然通知设备由某个地址指明的blocks不再需要了,SSD后面可以从FTL中清楚这个信息,然后在GC的时候再回收这部分空间。但Trim不能完全消除数据的碎片化,一般而言,顺序写到一个block的数据的生命期各不相同。因为FTL可能会自主的去合并那些数据。
根据之前讨论的,SSD有必要把相似生命期的数据放到同一个擦除块中。三星引入了这个概念,写数据之前,host system通过特殊的SSD命令按需打开stream。这些stream id主机系统和SSD都可见。上图是例子,如果1无效了,直接全部erase,没有copy开销。不过SSD自己可不知道数据的更新频率,所以这个ID不能由设备决定。
Linux通用块层回顾
linux系统中所有对存储设备的访问都离不开通用块层,对上它对文件系统和应用层提供访问存储设备的接口,对下它抽象出各种块设备并提供统一的框架供块设备驱动注册。
从源码中可以发现整个block layer涉及的两个核心数据结构分别为bio 和 request。
BIO请求单元
block layer 需要为文件系统或应用层提供一个基本的数据结构用于作为IO请求访问的基本单元。bio(struct bio)
/* 用于描述一个io请求数据段的三元组 */
struct bio_vec {
struct page *bv_page; /*数据段所属的内存页 */
unsigned short bv_len; /* 数据段在页内的长度 */
unsigned short bv_offset; /* 数据段在页内的起始偏移*/
};
struct bvec_iter {
sector_t bi_sector; /* 请求子块设备上的起始地址 */
unsigned int bi_size; /* 请求的大小 */
unsigned int bi_idx; /* 当前操作的 bi_io_vec成员 */
unsigned int bi_done; /* 已经处理完成的字节数 */
unsigned int bi_bvec_done; /* 已经处理完成的bi_io_vec数 */
};
/*
* bio 结构中的主要成员
*/
struct bio {
struct bio *bi_next; /* 用于链接到请求队列 */
blk_status_t bi_status; /* 请求的处理状态*/
struct block_device *bi_bdev; /* 请求对应的块设备 */
unsigned long bi_flags; /* 描述请求的状态 */
unsigned long bi_opf; /* 请求类型:读/写/冲刷 */
unsigned int bi_vcnt; /* bi_io_vec数组的大小 */
struct bvec_iter bi_iter; /* 当前操作的迭代器,保存了请求的
大小,在磁盘的位置 */
/*
* bi_io_vec中的数据段在有存在物理地址连续的,bi_phys_segments表示
* 地址连续的数据段聚合之后的数据段数量
*/
unsigned short bi_phys_segments;
unsigned int bi_max; /* bi_io_vec数组大小的上限 */
struct bio_vec *bi_io_vec; /* 指向保存io请求数据段的数组*/
bio_end_io_t *bi_end_io; /* 请求完成时的回调函数 */
atomic_t bi_cnt; /* bio的引用计数器 */
void *bi_private; /* 用于保存私有数据 */
};
各个 field 实际的含义如下图所示:
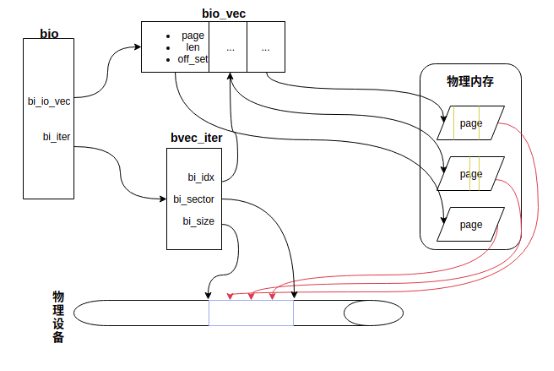
一个bio请求要读或者要写的数据在内存上可以不连续,每个不连续的数据段由bio_vec描述,但是所有的数据段在对应的磁盘上必须连续,这是由磁盘的物理特性决定的,单次IO只能操作一块连续的磁盘空间。bio结构包含的信息足以充当IO请求的基本单元,其贯穿于IO请求在通用块层处理的始末。
BIO产生和提交
block layer 提供了submit_bio 和 generic_make_request两个接口函数用于向通用块层提交bio, 其中submit_bio 是对 generic_make_request 的简单封装。在bio提交之前文件系统或者页高速缓存需要准备好bio结构,下面以对裸设备进行写操作为例分析bio产生过程,读操作时的bio生成逻辑类似,后面会在具体的IO场景分析中介绍。裸设备的写分为direct write 和 buffer write,两种场景下的write操作生成的bio过程不一样,前者是由文件系统直接派生bio,后者是页高速缓存下刷时派生bio。在linux世界中,一切皆文件,裸设备如/dev/sda也是一种文件,其在内核中也有对应的文件系统(块设备文件系统: fs/block_dev.c),文件系统操作表定义为:
const struct file_operations def_blk_fops = {
.open = blkdev_open,
.release = blkdev_close,
.llseek = block_llseek,
.read_iter = blkdev_read_iter,
.write_iter = blkdev_write_iter,
.mmap = generic_file_mmap,
.fsync = blkdev_fsync,
.unlocked_ioctl = block_ioctl,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = blkdev_fallocate,
};
文件系统一般还会提供页高速缓存的地址空间操作表,块设备文件系统的地址空间操作表为:
static const struct address_space_operations def_blk_aops = {
.readpage = blkdev_readpage,
.readpages = blkdev_readpages,
.writepage = blkdev_writepage,
.write_begin = blkdev_write_begin,
.write_end = blkdev_write_end,
.writepages = blkdev_writepages,
.releasepage = blkdev_releasepage,
.direct_IO = blkdev_direct_IO,
.is_dirty_writeback = buffer_check_dirty_writeback,
};
将metadata按照频率分为四个级别:
| stream | data |
|---|---|
| journal stream | journal |
| inode stream | inode table |
| directory stream | directory |
| misc stream | superblock, group descriptors, inode/block bitmap |
用户的APP可以通过 fcntl() 直接设定文件的write hint。