
FAST18 Protocol-Aware Recovery for Consensus-Based Storage
这篇文章是同事推荐做 paper reading 的,最近 oncall 期间也遇到了相关的生产问题,看看能不能有一些启发。
一 前言
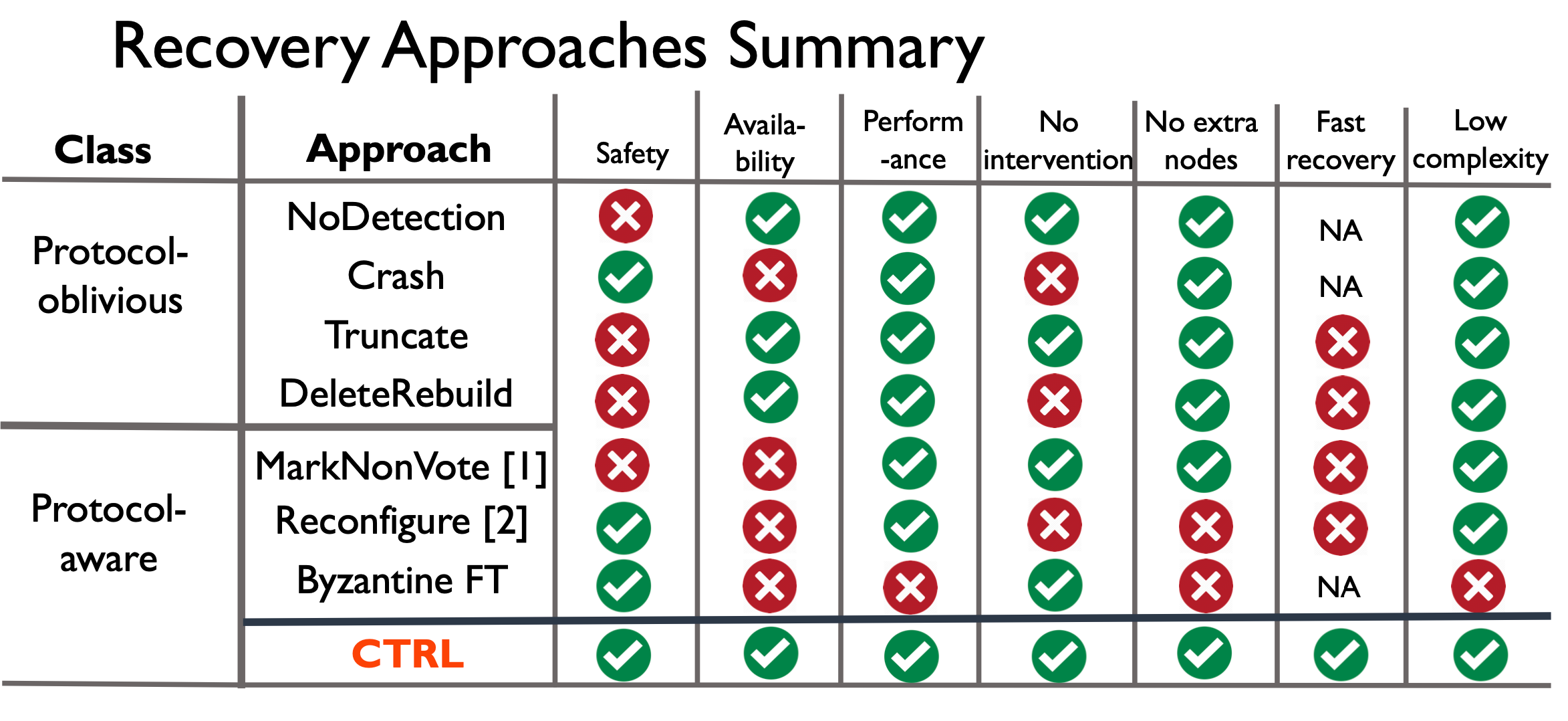
分布式系统中,存储故障挺常见的:1.corrupted (disk corruption) 2. corrupted (disk corruption)。一般故障恢复是通过冗余做到的,比如广泛采用的一个做法就是删除 faulty node 的数据然后重启。
但是粗暴地这么做,分布式系统的节点无法意识到 committed data 丢失了。比如当 majority 的一台机器数据销毁,不幸的是 leader 刚好收到了 majority ack 进行了 apply 操作,那么就会造成这部分日志丢失。我们说这种方式是不能利用察觉到分布式系统所使用的协议(Protocol-Oblivious)。既然存在这样的问题,作者提出了一种 Protocol-Aware Recovery (PAR) 的方法
文章作者主要将重心放在 Replicated State Machines (RSM) 上,因为大部分分布式系统都是采用了 RSM 作为模型。后面主要展示了他们的 CTRL 方法是如何利用 RSM 协议的特性来解决 safety 和 availability 问题的。
二 复制状态机
RSM 就是一种用于同步各个节点的状态机,状态机的初始状态是相同的,只要给定相同顺序的输入,一定产生相同顺序的输出,这样保证了数据的一致性,比如 raft 协议,就是确保 client 的指令在所有状态机上都是相同的顺序被执行。当然以上有一个前提,就是 log entry 被 commit apply 等等都是默认数据被持久化成功,不考虑持久化成功又失败的情况。
具体 raft 相关的部分还是回去参考 raft 论文。
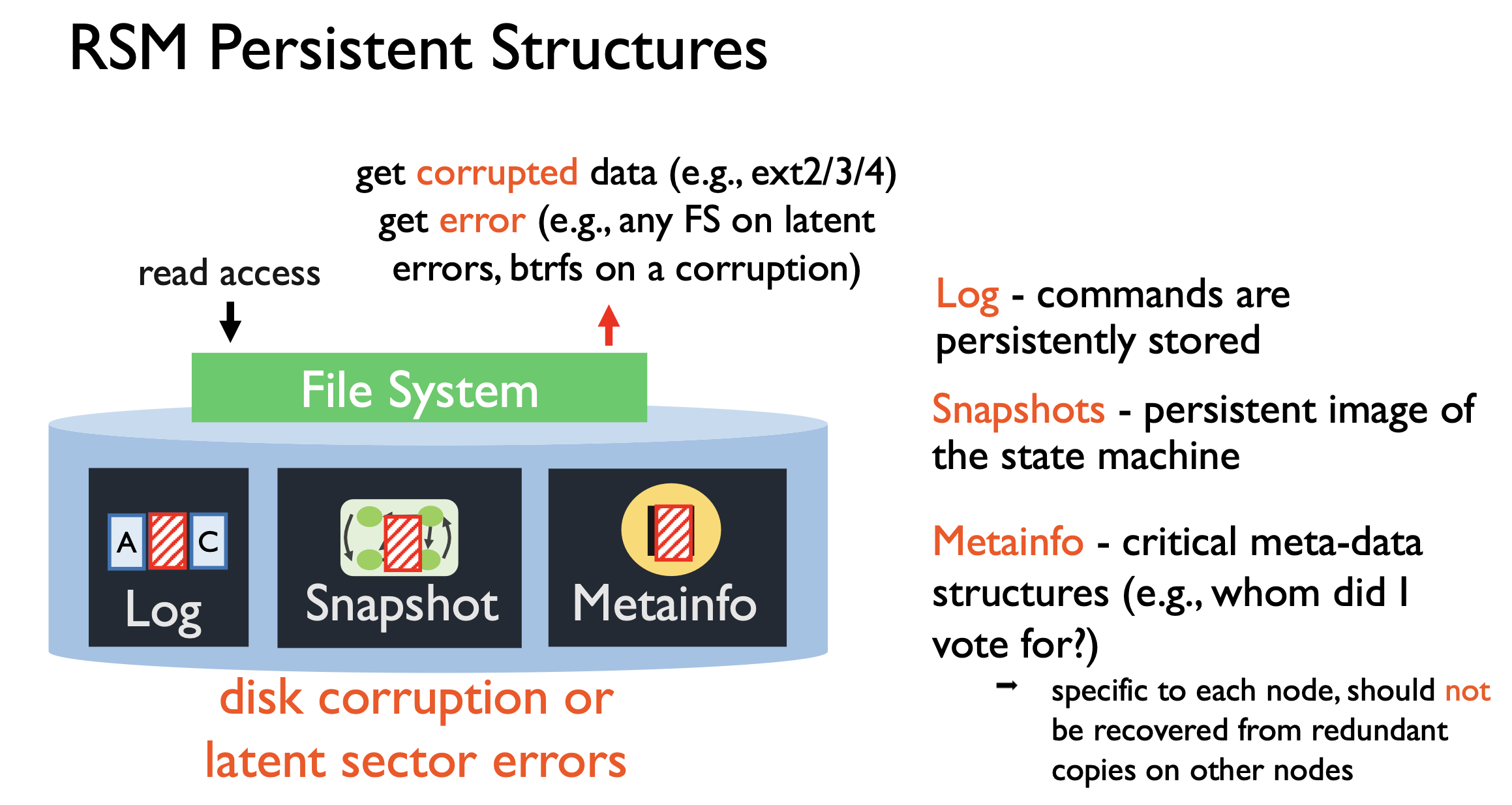
下面就是 RSM 持久化的结构:
三 背景
storage faults 可能由以下原因导致:存储介质问题、读取的扰动(比如内存被粒子击中)、固件或者驱动的错误、文件系统的 bug。错误表现形式主要是两类:block error 和 corruption,前者主要是类似扇区的错误,硬件自带了一些检测机制,而后者是写错导致的。
下面分析以下几个情况:Protocol-oblivious 即不关心分布式系统的具体协议,干就完事了;Protocol-aware 但是没处理好还是违背了协议的完备性。
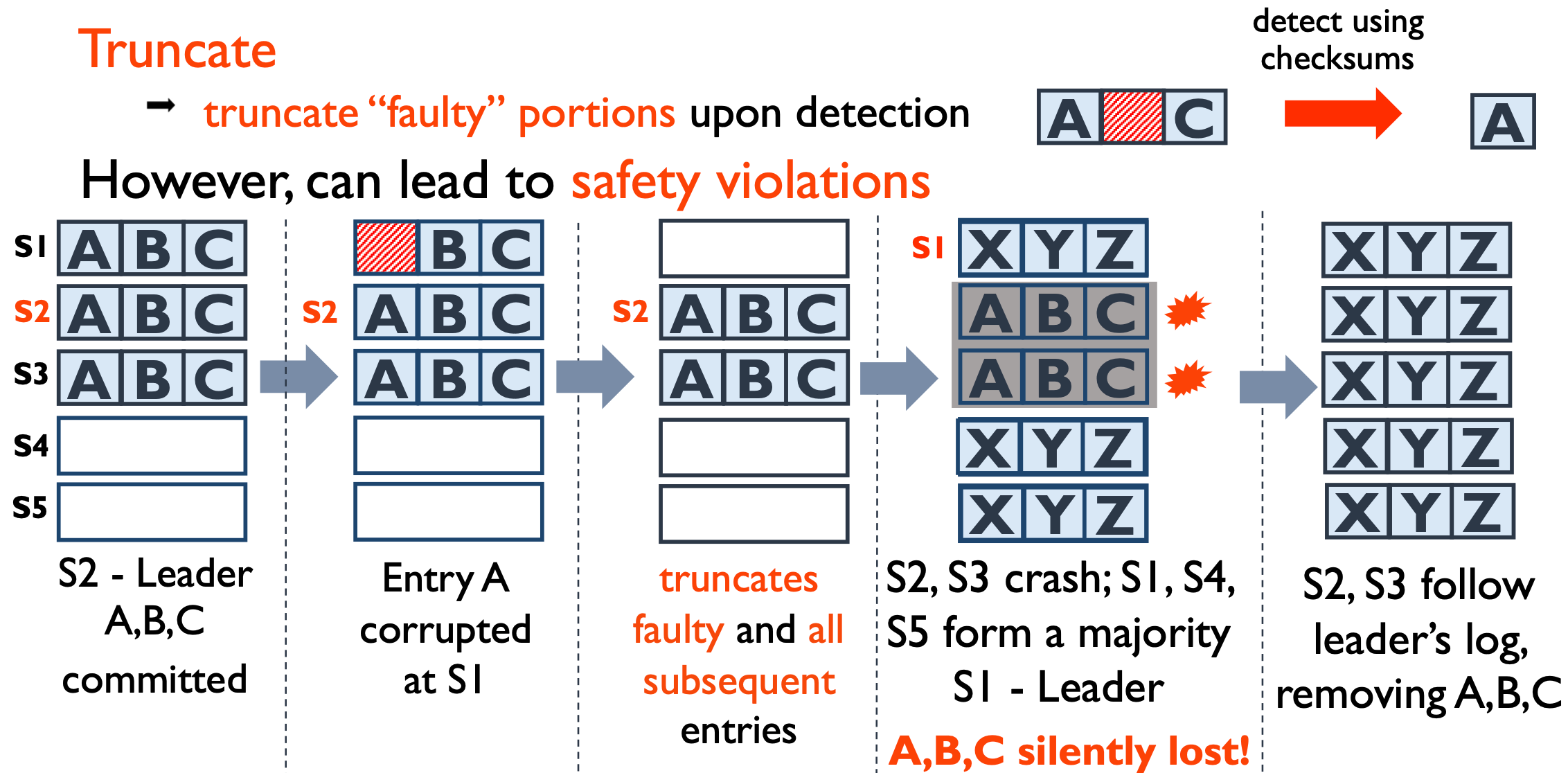
对于 Protocol-oblivious 又分成 crash 和 truncate 两种处理:crash 会将检测到 io 错误的节点直接挂掉,大部分实际的项目用的就是这个方法,简单粗暴,安全但是牺牲了一定的 availability,因为 crash 掉一个节点可能导致 majority 无法达成从而影响可用性;truncate 会把错误 entry 之后的全部截断,这样会发生的情况是 commit index 反向减小,如果从非 majority group 中恢复了数据,则造成数据正确性问题。
对于 Protocol-aware 调查了下面的几个方法:
MarkNonVoting: faulty node 删除所有数据,然后标记自己为 non-voting member,一直等到一轮共识进行完才从其他 nodes 重建数据。问题在于可能违背 safety,比如当曾经给 new leader 投过票的 promise 信息被删除了,那么就会继续接受 old leader 的 entry,而 new leader 认为该 node 给自己投票了,成为 leader 后就会用新的数据覆盖掉由 old leader commit 的 entry。 Reconfigure:移除发生faulty的节点,增加新节点。但是在 conf change 的变化期间不能对外服务。问题还是可用性问题。 BFT:拜占庭容错的场景。问题在于容错成本大,需要 3f+1 的节点。
总之,统计了各种方法,各有各的问题:
四 CTRL
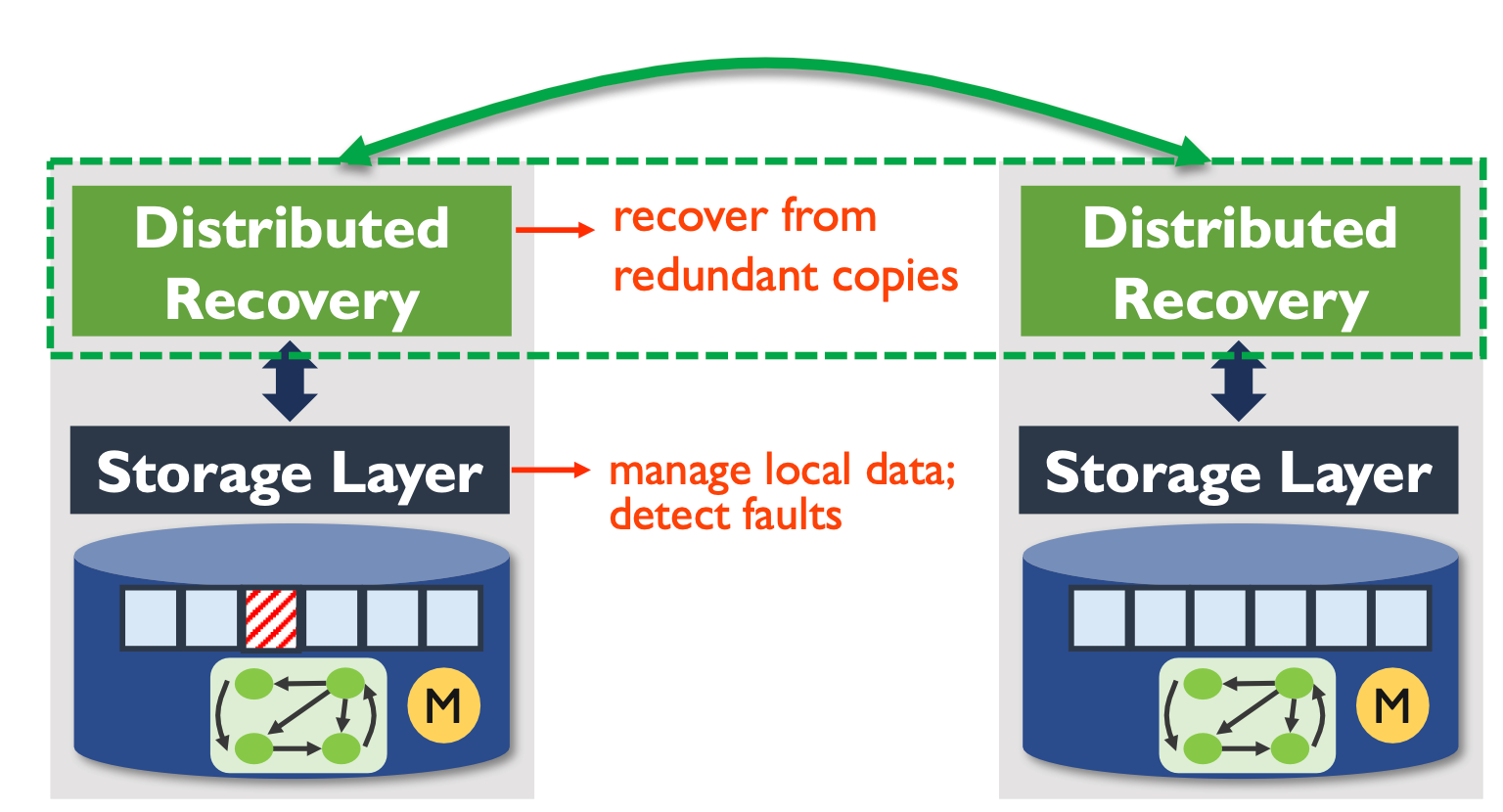
CTRL 由两部分组成:Local storage layer 和 Distributed recovery。前者检测本地节点的 faulty,后者用于从冗余副本恢复。
safety and availability guarantee
只要至少有一个正确的 committed data,那么 committed data 就不会丢失;
如果一个 committed data 的所有 copy 均丢失了,系统才会不可用。
1. Local storage layer
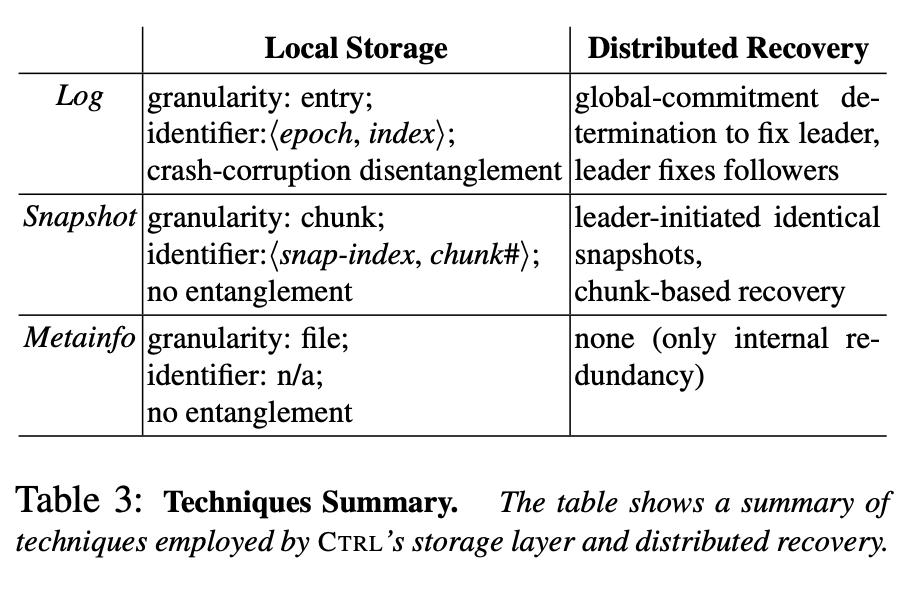
RSM 系统中一般由三个部分组成:log,snapshot,metainfo。
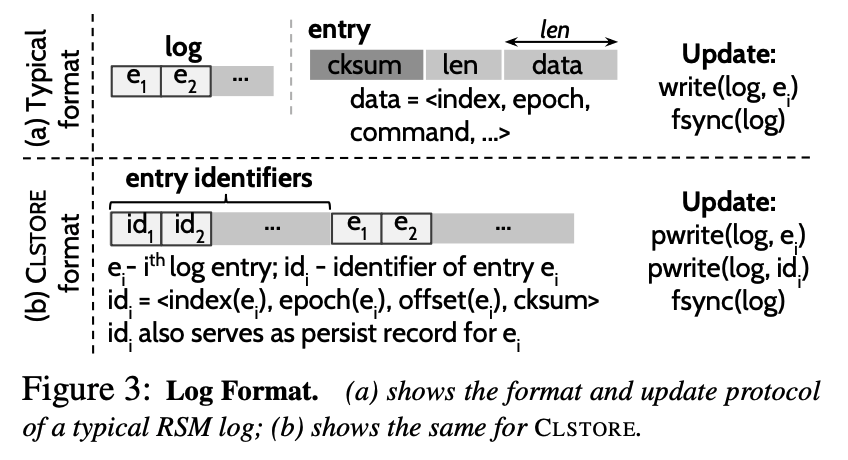
log:ctrl 将每个 entry 的识别符拆出来分开存储,下图结构。
snapshot:将其划分为 chunk 存储
metainfo:这个没法通过冗余恢复,因为是 local 相关的信息,包括投票信息等等,所以直接暴力存2份好了,一般就几十字节不会带来多少开销
检测 storage fault:通过 return code 来检测 inaccessible data;通过 checksum 来检测 corruption data。
一般 log 和 metainfo 更容易被检测,因为他们的 size 是固定的。当 metainfo 炸了,整个 node 就必须 crash 了,不过这个概率比较小,毕竟 meta 的大小远远小于 data 部分。
区分 crash 和 corruption:这2者很相似,都是由于 checksum 不过产生的问题。但 crash 是没写好导致的问题,可以被丢弃,但是 corruption 是中间的 log entry 坏掉了,需要进行恢复。那如何实现呢?答案是使用 commit record,比如写一个 entry ei 成功后,就在其后写入一个 pi,即 write(ei), fsync(), write(pi), fsync()
识别 faulty data:通过存储identifier来区分发生fault的entry,其中log的identifier是<epoch,index>,snapshot的identifier是<snap-index, chunk#>,可以保证每个entry都是唯一的,上述两个identifier分别占用32byte和12byte,因而可以保障原子写。为了防止entry和identifier同时出错,它们两个是在物理上分开存储的。
2. Distributed Log Recovery
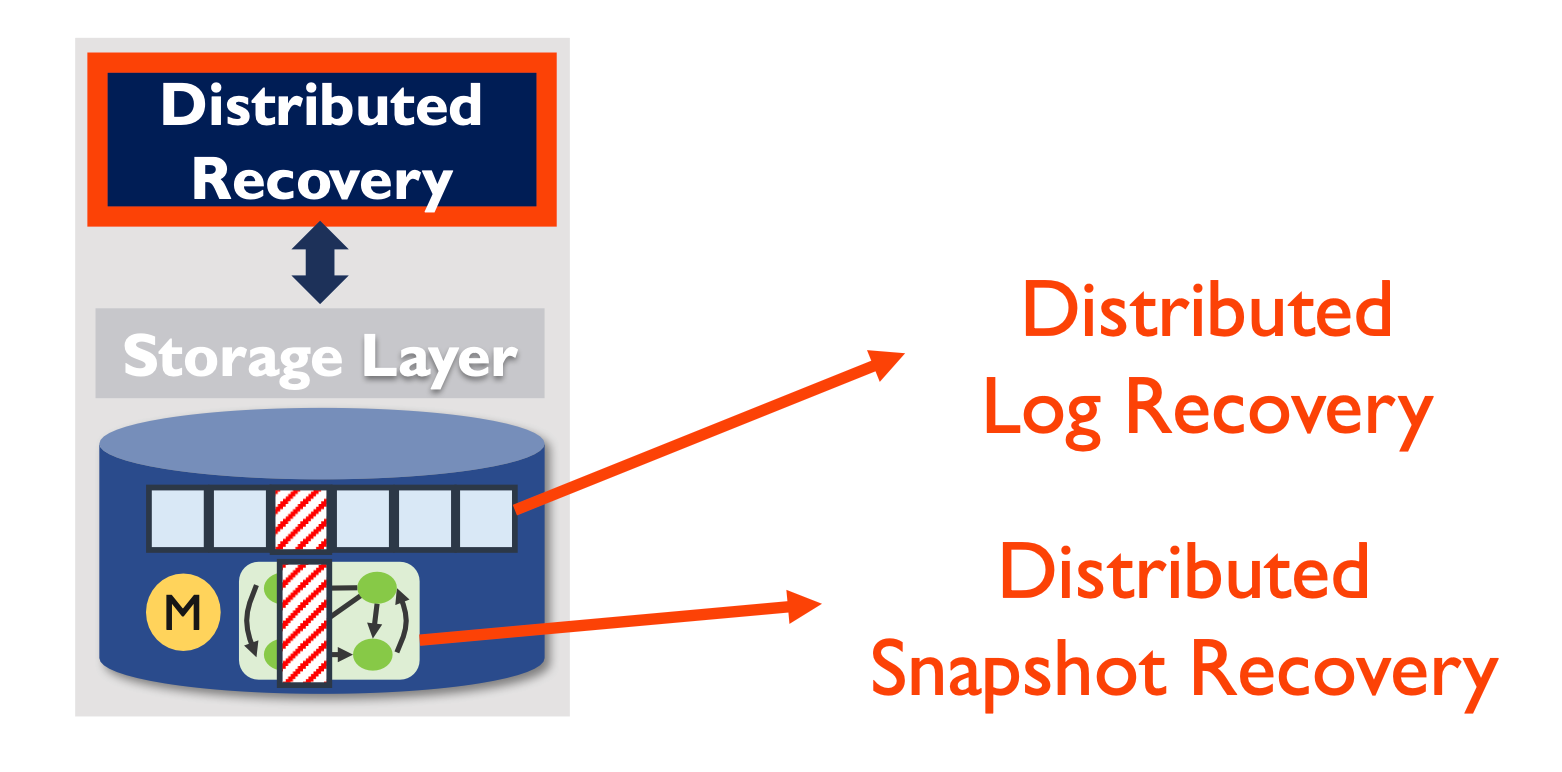
将follower recovery和leader recovery解耦,首先了解下本文中考虑storage fault时leader的限制。
实践中的共识协议具有的特点
leader-based
- 更新都要走 leader
epoch
- 每个 epoch 内只有一个 leader
leader 完备性
- leader 一定拥有所有 committed data
Leader的限制
1. 包含faulty entry的节点不能当选为leader(为了保证safty,不然可能从该节点中读取错误的数据);
2. leader必须具有最新最全的日志;
Follower recovery
follower 的 fix 非常简单,反正 leader 有其限制性,正常恢复即可。
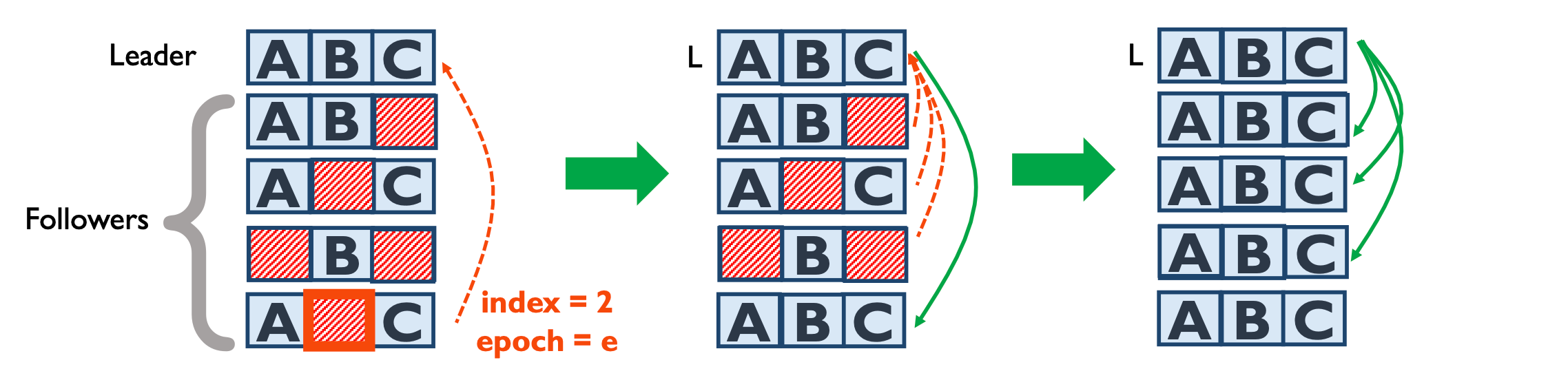
Leader recovery
leader 的恢复相对麻烦一点,简单的话还行,直接恢复,但应注意区分 committed 和 uncommitted entry,uncommitted entry 可以直接丢弃,越早丢弃影响可用性越小。
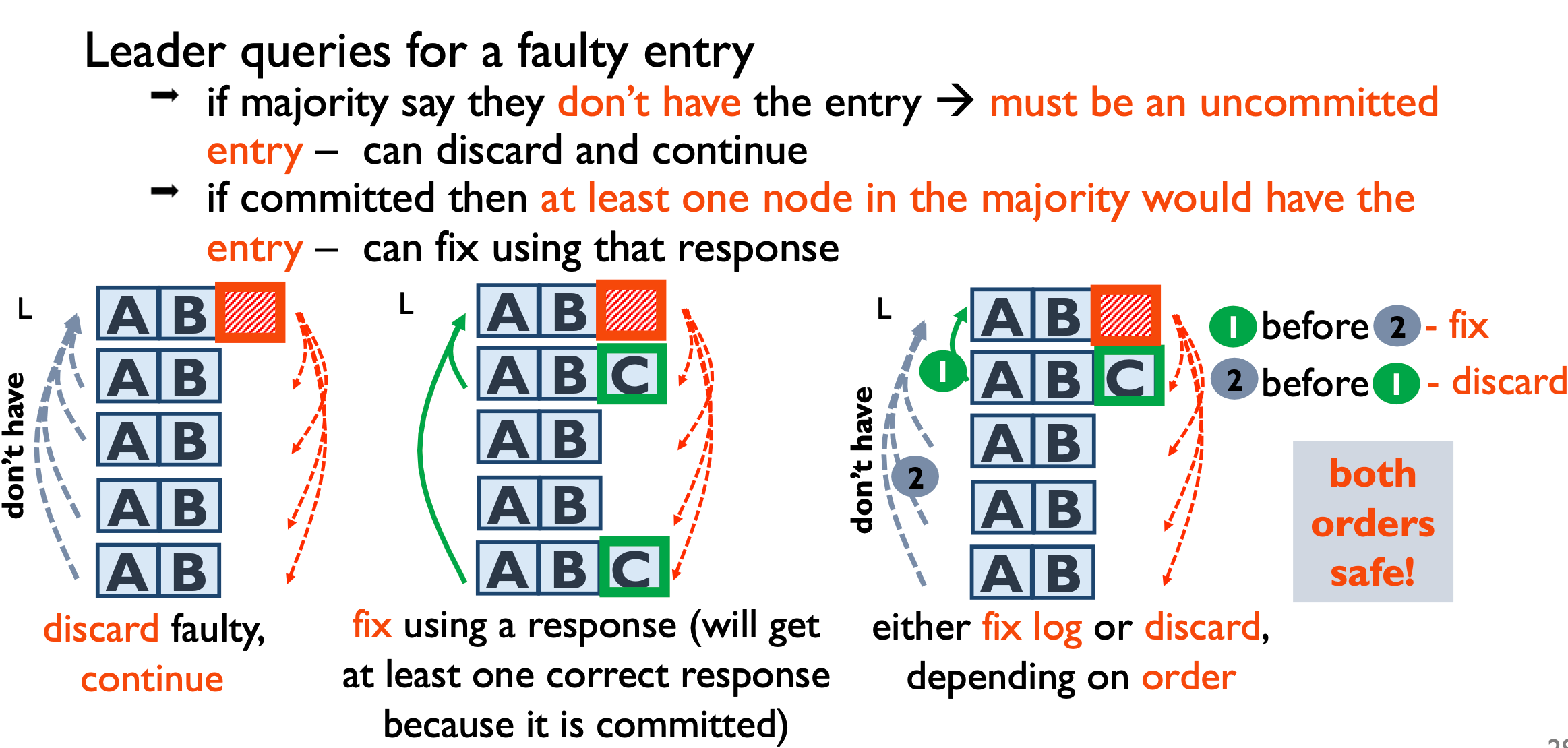
询问follower节点时会有三种 response:have、donthave、havefault
1、当至少有一个res是have时,表示节点中存在该entry,直接读取该entry进行恢复数据; 2、如果收到大多数的res是donthave,说明该entry是uncommited的,则将其与后面的entry都丢弃; 3、根据收到的res是havefault,这种情况指的是该follower节点中有entry,但是该entry是fault的。如下图所示,根据顺序,决定是丢弃还是修复,如果首先收到的是have,则是第1种的情况,否则是第2种情况;
这两种顺序都是安全的
Snapshot recovery
snapshot 的内容不能像 log 可以被 discarded,因为他们都是 applied 到 RSM 中的信息,所以相对处理比较麻烦。
改造
文章提到的 snapshot 有两个属性:1.当一个 snapshot 正在进行的时候,可以有 command applied 到另一个 snapshot 上;2.采用索引一致(index- consistent)snapshots,Si 即表示 apply 到第 i 个 entry 的状态机。CTRL 可以做到保护这两个属性的约束。
snapshot 在各个节点是独立进行的,意味着这个 Si 是不一样的,意味着不能直接拿其它节点的 snapshot 恢复。此外,也不能按照 chunks 来恢复,因为从整个 Snapshot 都不一样,意味着内部的 chunk 也是乱的。
如果每次进行 snapshot 都是相同的 index,至少可以解决索引一致带来的问题,这样可以直接拿其它冗余节点的 snapshot 恢复。而且也可以用 chunk 来恢复部分,毕竟 Si 都是一样的。
CTRL 是这么做的:
- Leader 每次 snapshot 的时候首先确定一个 index 通知所有 follower
- 多数 follower 共识后,就分别独立生成 Si
- 当 leader 确认 majority 在 index i 上进行了 snapshot后,对 i 之前的 log 进行垃圾回收,所有 follower 也进行同样操作
具体方案为:将上述的操作通过 log 进行,生成一个 marker 名为 snap 并共识出去,所有节点都会对在这个 marker 之前的 log 进行 snapshot,为了实现最早说的属性1,用 fork 的方式做,这样新的 command 继续工作互不影响。当 leader 确认所有 nodes 都 committed 了这个 snap 工作,再发一个 marker 为 gc。
恢复
前面改造了 snapshot 的机制后,恢复的过程就很容易理解了,local storage layer 检测到需要恢复的 snapshot index 和 chunk 后,由 distributed protocol recovery 组件从其它节点获取需要恢复的 chunks。
下面讨论三个情况:
-
需要恢复的部分对应的 log 未被 GC,从 log 里直接本地恢复即可
- GC 的话就从其它冗余节点恢复就行,因为 gc marker 之前必定已经被 majority 的节点 snapshot 过
- 当 follower 离线过久,导致请求的 Si 早已失效,leader 就会把最新的完整 snapshot 给
总结下 CTRL 的全部策略:
五 思考
TiKV 使用的方式为增量 snapshot,由 rocksdb 作为 snapshot 的存储引擎,而文章讨论的 snapshot 为每次全量写入。multi-raft 已经实现过对数据的一次切割,按理说已经实现了文章提到的分成 chunk 以降低 recovery 开销的效果了,所以看起来可以做到 remove peer 来实现,不过在线恢复的话,要考虑到这个 region 处于动态的 conf change 并且可能正在被使用的各种情况,文章提供的方法还是过于高层,实际做起来估计麻烦会不少。